
The Nelder-Mead method is a heuristic optimization technique, just like Genetic Algorithms or Particle Swarms. Optimization in this context refers to the problem of finding point(s) with the optimal value of an objective function in a search space. Optimal could mean a maximum or minimum value.
Whenever possible, we try to solve an optimization problem with an analytical method. For example, if you have the exact definition of 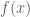

Heuristic optimization techniques try to remedy this by having a degree of randomness to them. This means that the same algorithm run with the same problem and the same initial conditions could yield different results with each run. Heuristic methods explore the search space stochastically, and keep a note of the ‘best’/most optimal points they come across on the way. Of course, the behaviour is not totally random, but guided by a set of rules.
The most important thing to remember is that heuristic methods never guarantee that they will find the most optimal solution. They give as an output the best point they came across during their search – which might have been a local optimum for all you know. But in practical scenarios, we usually concern ourselves with finding good solutions anyways- we don’t need them to be the best. In fact, finding the best solution with absolute certainty might be impossible/impractical in most cases (think of the stock market portfolio example again).
The Nelder-Mead method uses a geometrical shape called a simplex as its ‘vehicle’ of sorts to search the domain. This is why the technique is also called the Simplex search method. In layman’s terms, a simplex is the n-dimensional version of a ‘triangle’.
For 1 dimension, its a line.
![]()
For 2 dimensions, its a triangle.

For 3 dimensions, its a tetrahedron.

And so on…
The shape doesn’t have to be symmetrical/equilateral in any way. Note that an n-dimensional simplex has (n+1) vertexes.
The Algorithm
Nelder-Mead starts off with a randomly-generated simplex (We will discuss how, later). At every iteration, it proceeds to reshape/move this simplex, one vertex at a time, towards an optimal region in the search space. During each step, it basically tries out one or a few modifications to the current simplex, and chooses one that shifts it towards a ‘better’ region of the domain. In an ideal case, the last few iterations of this algorithm would involve the simplex shrinking inwards towards the best point inside it. At the end, the vertex of the simplex that yields that most optimal objective value, is returned.
The following video of a 2-D Nelder-Mead optimization should give you an intuitive understanding of what happens:
How does it work?
Lets assume we are dealing with an 

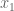
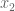

I. Ordering
All the points are ordered/sorted, such that the value of 
II. Computing the Centroid
Consider all points except the worst (

III. Transformation
This is the most important part of the whole process – transforming the simplex. Transformation takes place in one of the following ways:
i. Reflection
This is the first type of transformation that is tried out. You compute the ‘reflected’ point as:

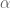


 Now, if
Now, if 
ii. Expansion
If our luck is great and the reflected point 

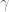

We then replace 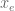

iii. Contraction
Suppose our reflection point was worst than 
The contraction point 


 If
If 
iv. Shrink contraction
In this case, we redefine the entire simplex. We only keep the best point (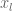


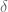

It is important to note that this transformation is the most expensive of all the transformations, since we have to replace multiple (all but one) points in the simplex. However, it has been found (after multiple experiments), that the shrink transformation rarely happens in practice. As a result, many implementations of Nelder-Mead simply skip this step, doing the Contraction instead.
Termination
Termination is usually reached when:
1. A given number of iterations is reached
2. The simplex reaches some minimum ‘size’ limit.
3. The current best solution reaches some favorable limit.
The Initial Simplex
Like in the case of most heuristic techniques, theres no ‘best’ way to do the random initialization for Simplex search. However, heres one that supposedly works well (it is used in the MATLAB implementation of Nelder-Mead):
The initial point, 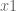
The (i + 1)th point 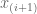

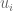

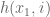


Other Points
1. Nelder-Mead is generally used for parameter selection in Machine Learning. In essence, data scientists use the Simplex Method to figure out the optimum parameters for their models. This is mainly because this method tends to optimize the objective function fairly fast, and in an efficient way (especially in implementations where Shrinking is not used).
2. Even though Nelder-Mead tends to optimize the objective fairly fast (with few iterations), it tends to get stuck in local optima. In such cases, it may remain stuck in a sub-optimal neighbourhood for a long time, and the only solution to this is to restart the algorithm. Why this happens is fairly easy to understand. Once the simplex enters a region of local optimum, it will only keep contracting/shrinking, instead of randomly exploring other(far-away) parts of the search space. As a result, its becomes impossible for the algorithm to explore any further.
3. Scipy implementation of Nelder-Mead.
References

Very clear and well explained, thanks! 😀
When you talk about parameter selection, do you encode the selection using a binary vector?
Not necessarily. The way I understand it, you could be optimizing something like a (learning rate, default neighbourhood value). In that case, the vector could even consist of floating point numbers.
Oh, that makes sense, as binary selection of parameters will lead to a too irregular landscape which, in turn, will make it impossible to escape local minima with this kind of an algorithm
Hello! Great blog. Did the image come from Jeff Heaton’s book?