A Bayesian Belief Network (BBN), or simply Bayesian Network, is a statistical model used to describe the conditional dependencies between different random variables.
BBNs are chiefly used in areas like computational biology and medicine for risk analysis and decision support (basically, to understand what caused a certain problem, or the probabilities of different effects given an action).
Structure of a Bayesian Network
A typical BBN looks something like this:

The shown example, ‘Burglary-Alarm‘ is one of the most quoted ones in texts on Bayesian theory. Lets look at the structural characteristics one by one. We will delve into the numbers/tables later.
Directed Acyclic Graph (DAG)
We obviously have one node per random variable.
Directed: The connections/edges denote cause->effect relationships between pairs of nodes. For example Burglary->Alarm in the above network indicates that the occurrence of a burglary directly affects the probability of the Alarm going off (and not the other way round). Here, Burglary is the parent, while Alarm is the child node.
Acyclic: There cannot be a cycle in a BBN. In simple English, a variable  cannot depend on its own value – directly, or indirectly. If this was allowed, it would lead to a sort of infinite recursion which we are not prepared to deal with. However, if you do realize that an event happening affects its probability later on, then you could express the two occurrences as separate nodes in the BBN (or use a Dynamic BBN).
cannot depend on its own value – directly, or indirectly. If this was allowed, it would lead to a sort of infinite recursion which we are not prepared to deal with. However, if you do realize that an event happening affects its probability later on, then you could express the two occurrences as separate nodes in the BBN (or use a Dynamic BBN).
Parents of a Node
One of the biggest considerations while building a BBN is to decide which parents to assign to a particular node. Intuitively, they should be those variables which most directly affect the value of the current node.
Formally, this can be stated as follows: “The parents of a variable  (
(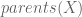 ) are the minimal set of ancestors of , such that all other ancestors of are conditionally independent of given “.
) are the minimal set of ancestors of , such that all other ancestors of are conditionally independent of given “.
Lets take this step by step. First off, there has to be some sort of a cause-effect relationship between  and for to be one of the ancestors of . In the shown example, the ancestors of Mary Calls are Burglary, Earthquake and Alarm.
and for to be one of the ancestors of . In the shown example, the ancestors of Mary Calls are Burglary, Earthquake and Alarm.
Now consider the two ancestors Alarm and Earthquake. The only way an Earthquake would affect Mary Calls, is if an Earthquake causes Alarm to go off, leading to Mary Calls. Suppose someone told you that Alarm has in fact gone off. In this case, it does not matter what lead to the Alarm ringing – since Mary will react to it based on the stimulus of the Alarm itself. In other words, Earthquake and Mary Calls become conditionally independent if you know the exact value of Alarm.
Mathematically speaking, 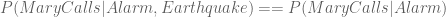 .
.
Thus, are those ancestors which do not become conditionally independent of given the value of some other ancestor. If they do, then the resultant connection would actually be redundant.
Disconnected Nodes are Conditionally Independent
Based on the directed connections in a BBN, if there is no way to go from a variable to (or vice versa), then and are conditionally independent. In the example BBN, pairs of variables that are conditionally independent are {Mary Calls, John Calls} and {Burglary, Earthquake}.
It is important to remember that ‘conditionally independent’ does not mean ‘totally independent’. Consider {Mary Calls, John Calls}. Given the value of Alarm (that is, whether the Alarm went off or not), Mary and John each have their own independent probabilities of calling. However, if you did not know about any of the other nodes, but just that John did call, then your expectation of Mary calling would correspondingly increase.
Mathematics behind Bayesian Networks
BBNs provide a mathematically correct way of assessing the effects of different events (or nodes, in this context) on each other. And these assessments can be made in either direction – not only can you compute the most likely effects given the values of certain causes, but also determine the most likely causes of observed events.
The numerical data provided with the BBN (by an expert or some statistical study) that allows us to do this is:
- The prior probabilities of variables with no parents (Earthquake and Burglary in our example).
- The conditional probabilities of any other node given every value-combination of its parent(s). For example, the table next to Alarm defines the probability that the Alarm will go off given the whether an Earthquake and/or Burglary have occurred.
In case of continuous variables, we would need a conditional probability distribution.
The biggest use of Bayesian Networks is in computing revised probabilities. A revised probability defines the probability of a node given the values of one or more other nodes as a fact. Lets take an example from the Burglary-Alarm BBN.
Suppose we want to calculate the probability that an earthquake occurred, given that the alarm went off, but there was no burglary. Essentially, we want  . Simplifying the nomenclature a bit,
. Simplifying the nomenclature a bit,  .
.
Here, you can say that the Alarm going off () is evidence, the knowledge that the Burglary did not happen (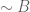 ) is context and the Earthquake occurring (
) is context and the Earthquake occurring (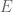 ) is the hypothesis. Traditionally, if you knew nothing else,
) is the hypothesis. Traditionally, if you knew nothing else,  , from the diagram. However, with the context and evidence in mind, this probability gets changed/revised. Hence, its called ‘computing revised probabilities’.
, from the diagram. However, with the context and evidence in mind, this probability gets changed/revised. Hence, its called ‘computing revised probabilities’.
A version of Bayes Theorem states that
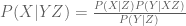 …(1)
…(1)
where is the hypothesis, is the evidence, and  is the context. The numerator on the RHS denotes that probability that & both occur given , which is a subset of the probability that atleast occurs given , irrespective of .
is the context. The numerator on the RHS denotes that probability that & both occur given , which is a subset of the probability that atleast occurs given , irrespective of .
Using (1), we get
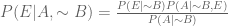 …(2)
…(2)
Since and 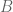 are independent phenomena without knowledge of ,
are independent phenomena without knowledge of ,
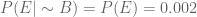 …(3)
…(3)
From the table for ,
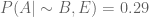 …(4)
…(4)
Finally, using the Total Probability Theorem,
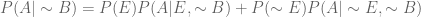 …(5)
…(5)
Which is nothing but average of 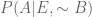 &
&  , weighted on
, weighted on 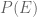 &
& 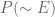 respectively.
respectively.
Substituting values in (5),
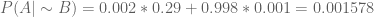 …(6)
…(6)
From (2), (3), (4), & (6), we get

As you can see, the probability of the Earthquake actually increases if you know that the Alarm went off but a Burglary was not the cause of it. This should make sense intuitively as well. Which brings us to the final part –
The ‘Explain Away’ Effect
The Explain Away effect, commonly associated with BBNs, is a result of computing revised probabilities. It refers to the phenomenon where knowing that one cause has occurred, reduces (but does not eliminate) the probability that the other cause(s) took place.
Suppose instead of knowing that there has been no burglary like in our example, you infact did know that one has taken place. It also led to the Alarm going off. With this information in mind, your tendency to check out the ‘earthquake’ hypothesis reduces drastically. In other words, the burglary has explained away the alarm.
It is important to note that the probability for other causes just gets reduced, but does NOT go down to zero. In a stroke of bad luck, it could have happened that both a burglary and an earthquake happened, and any one of the two stimuli could have led to the alarm ringing. To what extent you can ‘explain away’ an evidence depends on the conditional probability distributions.

