What is Boosting?
Boosting is a machine learning meta-algorithm that aims to iteratively build an ensemble of weak learners, in an attempt to generate a strong overall model.
Lets look at the highlighted parts one-by-one:
1. Weak Learners: A ‘weak learner’ is any ML algorithm (for regression/classification) that provides an accuracy slightly better than random guessing. For example, consider a problem of binary classification with approximately 50% of samples belonging to each class. Random guessing in this case would yield an accuracy of around 50%. So a weak learner would be any algorithm, however simple, that slightly improves this score – say 51-55% or more. Usually, weak learners are pretty basic in nature. Some examples are Decision Stumps or smaller Decision Trees. In most cases, either one of these two is used as a weak learner in Boosting frameworks.
2. Ensemble: The overall model built by Boosting is a weighted sum of all of the weak learners. The weights and training given to each ensures that the overall model yields a pretty high accuracy (sometimes state-of-the-art).
3. Iteratively build: Many ensemble methods such as bagging/random forests are capable of training their components in parallel. This is because the training of any of those weak learners does not depend on the training of the others. That is not the case with Boosting. At each step, Boosting tries to evaluate the shortcomings of the overall model built till the previous step, and then generates a weak learner to battle these shortcomings. This weak learner is then added to the total model. Therefore, the training must necessarily proceed in a serial/iterative manner.
4. Meta-algorithm: Since Boosting isn’t necessarily an ML algorithm by itself, but rather uses other (basic) algorithms to build a stronger one, it is said to be a ‘meta’ algorithm.
How does Boosting work?

Usually, a Boosting framework for regression works as follows:
(The overall model at step ‘i’ is denoted by 
1. Start with a simple model 
2. For 
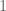
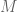
2.a) Evaluate the shortcomings of 
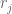
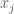
2.b) Generate a new weak learner 
2.c) Compute the corresponding weight 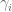
2.d) Update the current model as follows:
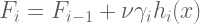
where 
3. Return 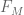
Each of the iterations in Boosting essentially tries to ‘improve’ the current model by introducing another learner into the ensemble. Having such an ensemble not only reduces the bias (which is generally pretty high for weak learners), but also the variance (since multiple learners contribute to the overall output, each with their own unique training). There are various versions of Boosting, and all of them primarily differ in the way they perform steps 2.a, 2.b. and 2.c.
For example, Gradient Boosting computes 

AdaBoost, short for Adaptive Boosting, works by assigning
The weak-learners used in Boosting are indeed ‘weak’. The most commonly used ones are decision trees of a fixed number of leaf nodes. Using complex methods such as SVMs in Boosting usually leads to overfitting. However, the total number of weak learners
To improve the bias/variance characteristics of Boosting, bagging is generally employed. What this essentially does is train each weak learner on a subset of the overall dataset (rather than the whole training set). This causes a good decrease in variance and tends to reduce overfitting.
Classification applications would work slightly different from regression, of course. The most commonly used method is to build a boosted model for each class. This model would predict the probability of a data point belonging to that class. During training, the inputs belonging to the corresponding class will be given a target of 1, with the others getting a target of 0. The outputs from all the models could then be put into a softmax function for normalization.
What are the drawbacks of Boosting?
The most obvious drawback of boosting is the computational complexity. Performing so many iterations, and generating a new model at each, requires a lot of computations and time (and also space). The fact that the ensemble has to be built iteratively doesn’t help matters. However, using simple weak learners (instead of big decision trees) helps to mitigate this problem.
The biggest criticism for Boosting comes from its sensitivity to noisy data. Think of it this way. At each iteration, Boosting tries to improve the output for data points that haven’t been predicted well till now. If your dataset happens to have some (or a lot) of misclassified/outlier points, the meta-algorithm will try very hard to fit subsequent weak learners to these noisy samples. As a result, overfitting is likely to occur. The exponential loss function used in AdaBoost is particularly vulnerable to this issue (since the error from an outlier will get an exponentially-weighed importance for future learners).

For Adaboost there’s a typo: it’s F i-1 not F i-i.
Is there a name for using bagging to improve boosting?
Thx for the article, really clear!
Thanks! Fixed the typo :-).
As for the name, I think the version is said to be ‘Stochastic’. So Gradient Boosting with bagging is called Stochastic Gradient Boosting.
Do you have a reference for this being one of the best out-of-the-box classifiers? I’ve never heard that before I visited wikipedia, and I’m not sure it’s actually true, or been demonstrated with a solid statistical backing.