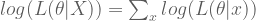Anyone who has done some course in statistics or data science, must have come across the term ‘likelihood’. In non-technical language, likelihood is synonymous with probability. But ask any mathematician, and their interpretation of the two concepts is significantly different. I went digging into likelihood for a bit this week, so thought of putting down the basics of what I revisited.
Whenever we talk about understanding data, we talk about models. In statistics, a model is usually some sort of parameterized function – like a probability density function (pdf) or a regression model. But the effectiveness of the model’s outputs will only be as good as its fit to the data. If the characteristics of the data are very different from the assumed model, the bias turns out to be pretty high. So from a probability perspective, how do we quantify this fit?
Defining the Likelihood Function
The two entities of interest are – the data 
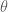

There are two practical ways you could deal with this function. If you kept 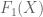
But in real life, you rarely know your model with certainty. What you do have, is a bunch of observed data. So shouldn’t we also think of the other way round? Suppose you kept 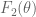
Mind you, in both cases, the underlying mathematical definition is the same. The input ‘variable’ is what has changed. This is how probability and likelihood are related. The function 
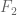
The above definition might make you think that the likelihood is nothing but a rewording of probability. But keeping the data constant, and varying the parameters has huge consequences on the way you interpret the resultant function.
Lets take a simple example. Consider you have a set 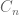


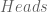

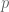
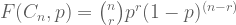
Now suppose you made coin yourself, so you know 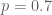
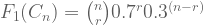
On the other hand, lets say you don’t know much about the coin, but you do have a bunch of toss-outcomes from it. You made 10 different tosses, out which 5 were
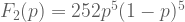
There is a very, very important distinction between probability and likelihood functions – the value of the probability function sums (or integrates, for continuous data) to 1 over all possible values of the input data. However, the value of the likelihood function does not integrate to 1 over all possible combinations of the parameters.
The above statement leads to the second important thing to note: DO NOT interpret the value of a likelihood function, as the probability of the model parameters. If your probability function gave the value of 0.7 (say) for a discrete data point, you could be pretty sure that there would be no other option as likely as it. This is because, the sum of the probabilities of all other point would be equal to 0.3. However, if you got 0.99 as the output of your likelihood function, it wouldn’t necessarily mean that the parameters you gave in are the most likely ones. Some other set of parameters might give 0.999, 0.9999 or something higher.
The only thing you can be sure of, is this: If 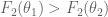

Log Likelihoods for Maximum Likelihood Estimation
The likelihood function is usually denoted as 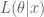

Maximum Likelihood Estimation usually involves computing the partial derivative of the likelihood function with respect to the parameters. We generally deal with the log-likelihood (basically the logarithm of the likelihood function) rather than likelihood itself. Since log is a monotonically increasing function, the optimum value of the likelihood function can be calculated using derivatives of log-likelihood as well. The reason we use logarithms, is to make the process of dealing with derivatives easy. Consider the coin-toss example I gave above:
Your Likelihood function for the probability of

Computing log, we get
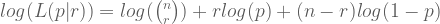
To maximise, we will compute the partial derivative with respect to
Using 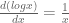

Solving, we get the intuitive result:

In most cases, when you compute likelihood, you would be dealing with a bunch of independent data points 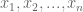

Using log, the overall likelihood becomes: