Mind Maps are notorious for being a very powerful organizational tool for a variety of tasks, such as brainstorming, planning and problem solving. Visual (or rather, graphical) arrangement of ideas aids the thought process, and in fact mimics the way we explore our mental knowledge base while ‘thinking’. There are a lot of online tools available for drawing out mind maps, but none that can generate one. By generate, I mean coming up with the verbal content.
For the longest time (almost 8 months now), I have been tinkering with ways to combine text mining and graph theory into a framework to generate a Mind-Map (given a text document). Ofcourse, the first thing argument would be that there cannot be a single possible Mind-Map for any block of text. And its true! However, having such an automated Map as a reference while building your own, might give you more insights (especially while brainstorming), or help you remember links that you might miss out (for studying). Lets see what a Mind-Map looks like:

Two points:
i. A Mind-Map is NOT a tree that divides the overall topic into its subtopics recursively. Its infact more like a graph, that links terms that are semantically related.
ii. Like ‘Night’ might make the word ‘Day’ pop up in your mind, a mind-map may have links between opposite meaning concepts, like Thicker-Thinner in the above example.
There are of course other points like using images to enhance concepts, and so on. But thats not the point of this post (And I suck at designer-style creativity anyways). Heres an article to help you get acquainted with the process of building and using your own Mind-Maps, just in case.
In my last post, I described a method to generate a Word2Vec model from a text document (where I used Wikipedia articles as an example). I will now describe the methodology I followed to generate a rudimentary mind-map from a Wikipedia article’s Word2Vec model model.
Step 1: Figuring out the top n terms from the document
(As I mentioned in my previous post, I only use stemmed unigrams. You can of course use higher-order ngrams, but that makes things a little tricky (but more accurate, if your algorithms for n-gram generation are solid).)
Here, n denotes the number of ‘nodes’ in my Mind-Map. In my trial-and-errors, 50 is usually a good enough number. Too less means too little information, and too much would mean noisy mind-maps. You can obviously play around with different choices of n. I use the co-occurrence based technique described in this paper to list out the top n words in a document. Heres the Python code for it:
def _get_param_matrices(vocabulary, sentence_terms):
"""
Returns
=======
1. Top 300(or lesser, if vocab is short) most frequent terms(list)
2. co-occurence matrix wrt the most frequent terms(dict)
3. Dict containing Pg of most-frequent terms(dict)
4. nw(no of terms affected) of each term(dict)
"""
#Figure out top n terms with respect to mere occurences
n = min(300, len(vocabulary))
topterms = list(vocabulary.keys())
topterms.sort(key = lambda x: vocabulary[x], reverse = True)
topterms = topterms[:n]
#nw maps term to the number of terms it 'affects'
#(sum of number of terms in all sentences it
#appears in)
nw = {}
#Co-occurence values are wrt top terms only
co_occur = {}
#Initially, co-occurence matrix is empty
for x in vocabulary:
co_occur[x] = [0 for i in range(len(topterms))]
#Iterate over list of all sentences' vocabulary dictionaries
#Build the co-occurence matrix
for sentence in sentence_terms:
total_terms = sum(list(sentence.values()))
#This list contains the indices of all terms from topterms,
#that are present in this sentence
top_indices = []
#Populate top_indices
top_indices = [topterms.index(x) for x in sentence
if x in topterms]
#Update nw dict, and co-occurence matrix
for term in sentence:
nw[term] = nw.get(term, 0) + total_terms
for index in top_indices:
co_occur[term][index] += (sentence[term] *
sentence[topterms[index]])
#Pg is just nw[term]/total vocabulary of text
Pg = {}
N = sum(list(vocabulary.values()))
for x in topterms:
Pg[x] = float(nw[x])/N
return topterms, co_occur, Pg, nw
def get_top_n_terms(vocabulary, sentence_terms, n=50):
"""
Returns the top 'n' terms from a block of text, in the form of a list,
from most important to least.
'vocabulary' should be a dict mapping each term to the number
of its occurences in the entire text.
'sentence_terms' should be an iterable of dicts, each denoting the
vocabulary of the corresponding sentence.
"""
#First compute the matrices
topterms, co_occur, Pg, nw = _get_param_matrices(vocabulary,
sentence_terms)
#This dict will map each term to its weightage with respect to the
#document
result = {}
N = sum(list(vocabulary.values()))
#Iterates over all terms in vocabulary
for term in co_occur:
term = str(term)
org_term = str(term)
for x in Pg:
#expected_cooccur is the expected cooccurence of term with this
#term, based on nw value of this and Pg value of the other
expected_cooccur = nw[term] * Pg[x]
#Result measures the difference(in no of terms) of expected
#cooccurence and actual cooccurence
result[org_term] = ((co_occur[term][topterms.index(x)] -
expected_cooccur)**2/ float(expected_cooccur))
terms = list(result.keys())
terms.sort(key=lambda x: result[x],
reverse=True)
return terms[:n]
The get_top_n_terms function does the job, and I guess the docstrings and in-line comments explain how (combined with the paper, of course). If you have the patience and time, you can infact just see the entire vocabulary of your Word2Vec model and pick out those terms that you want to see in your Mind-Map. This is likely to give you the best results (but with a lot of efforts).
Step 2: Deciding the Root
The Root would be that term out of your nodes, which denotes the central idea behind your entire Mind-Map. Since the number of nodes is pretty small compared to the vocabulary, its best to pick this one out manually. OR, you could use that term which has the highest occurrence in the vocabulary, among the selected nodes. This step may require some trial and error (But then what part of data science doesn’t?).
Step 3: Generating the graph (Mind-Map)
This is of course the most crucial step, and the one I spent the most time on. First off, let me define what I call the contextual vector of a term.
Say the root of the Mind Map is ‘computer’. It is linked to the term ‘hardware’. ‘hardware’ is in turn linked to ‘keyboard’. The Word2Vec vector of ‘keyboard’ would be obtained as model[keyboard] in the Python/Gensim environment. Lets denote it with 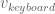
Now consider yourself in the position of someone building a Mind Map. When you think of ‘keyboard’, given the structure of what you have come up with so far, you will be thinking of it in the context of ‘computer’ and ‘hardware’. Thats why you probably won’t link ‘keyboard’ to ‘music’ (atleast not directly). This basically shows that the contextual vector for ‘keyboard’ (lets call it 
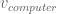

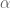

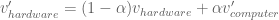

And so on…
Finally, to generate the actual Mind-Map, heres the algorithm I use (I hope the inline comments are enough to let you know what I have done):
from scipy.spatial.distance import cosine
from networkx import Graph
def build_mind_map(model, stemmer, root, nodes, alpha=0.2):
"""
Returns the Mind-Map in the form of a NetworkX Graph instance.
'model' should be an instance of gensim.models.Word2Vec
'nodes' should be a list of terms, included in the vocabulary of
'model'.
'root' should be the node that is to be used as the root of the Mind
Map graph.
'stemmer' should be an instance of StemmingHelper.
"""
#This will be the Mind-Map
g = Graph()
#Ensure that the every node is in the vocabulary of the Word2Vec
#model, and that the root itself is included in the given nodes
for node in nodes:
if node not in model.vocab:
raise ValueError(node + " not in model's vocabulary")
if root not in nodes:
raise ValueError("root not in nodes")
##Containers for algorithm run
#Initially, all nodes are unvisited
unvisited_nodes = set(nodes)
#Initially, no nodes are visited
visited_nodes = set([])
#The following will map visited node to its contextual vector
visited_node_vectors = {}
#Thw following will map unvisited nodes to (closest_distance, parent)
#parent will obviously be a visited node
node_distances = {}
#Initialization with respect to root
current_node = root
visited_node_vectors[root] = model[root]
unvisited_nodes.remove(root)
visited_nodes.add(root)
#Build the Mind-Map in n-1 iterations
for i in range(1, len(nodes)):
#For every unvisited node 'x'
for x in unvisited_nodes:
#Compute contextual distance between current node and x
dist_from_current = cosine(visited_node_vectors[current_node],
model[x])
#Get the least contextual distance to x found until now
distance = node_distances.get(x, (100, ''))
#If current node provides a shorter path to x, update x's
#distance and parent information
if distance[0] > dist_from_current:
node_distances[x] = (dist_from_current, current_node)
#Choose next 'current' as that unvisited node, which has the
#lowest contextual distance from any of the visited nodes
next_node = min(unvisited_nodes,
key=lambda x: node_distances[x][0])
##Update all containers
parent = node_distances[next_node][1]
del node_distances[next_node]
next_node_vect = ((1 - alpha)*model[next_node] +
alpha*visited_node_vectors[parent])
visited_node_vectors[next_node] = next_node_vect
unvisited_nodes.remove(next_node)
visited_nodes.add(next_node)
#Add the link between newly selected node and its parent(from the
#visited nodes) to the NetworkX Graph instance
g.add_edge(stemmer.original_form(parent).capitalize(),
stemmer.original_form(next_node).capitalize())
#The new node becomes the current node for the next iteration
current_node = next_node
return g
Notes: I use NetworkX’s simple Graph-building infrastructure to do the core job of maintaining the Mind-Map (makes it easier later for visualization too). To compute cosine distance, I use SciPy. Moreover, on lines 74 and 75, I use the StemmingHelper class from my last post to include the stemmed words in their original form in the actual mind-map (instead of their stemmed versions). You can pass the StemmingHelper class directly as the parameter stemmer. On the other hand, if you aren’t using stemming at all, just remove those parts of the code on lines 4, 74, and 75.
If you look at the algorithm, you will realize that its somewhat like Dijkstra’s algorithm for single-source shortest paths, but in a different context.
Example Outputs
Now for the results. (I used PyGraphViz for simple, quick-and-dirty visualization)
Heres the Mind-Map that was generated for the Wikipedia article on Machine Learning:

One on Artificial Intellgence:
 And finally, one on Psychology:
And finally, one on Psychology:

The results are similar on all the other topics I tried out. A few things I noticed:
i. I should try and involve bi-grams and trigrams too. I am pretty sure it will make the Word2Vec model itself way stronger, and thus improve the interpretation of terms with respect to the document.
ii. There are some unnecessary terms in the Mind Maps, but given the short length of the texts (compared to most text mining tasks), the Keyword extraction algorithm in the paper I mentioned before, seems really good.
iii. Maybe one could use this for brainstorming. Like you start out with a term(node) of your choice. Then, the framework suggests you terms to connect it to. Once you select one of them, you get further recommendations for it based on the context, etc. – Something like a Mind-Map helper.
Anyways, this was a long post, and thanks a lot if you stuck to the end :-). Cheers!

Very cool work!