“Apply Machine Learning like the great engineer you are, not like the great Machine Learning expert you aren’t.”
This is the first sentence in a Google-internal document I read about how to apply ML. And rightly so. In my limited experience working as a server/analytics guy, data (and how to store/process it) has always been the source of most consideration and impact on the overall pipeline. Ask any Kaggle winner, and they will always say that the biggest gains usually come from being smart about representing data, rather than using some sort of complex algorithm. Even the CRISP data mining process has not one, but two stages dedicated solely to data understanding and preparation.
So what is Feature Engineering?
Simply put, it is the art/science of representing data is the best way possible.
Why do I say art/science? Because good Feature Engineering involves an elegant blend of domain knowledge, intuition, and basic mathematical abilities. Heck, the most effective data representation ‘hacks’ barely involve any mathematical computation at all! (As I will explain in a short while).
What do I mean by ‘best’? In essence, the way you present your data to your algorithm should denote the pertinent structures/properties of the underlying information in the most effective way possible. When you do feature engineering, you are essentially converting your data attributes into data features.
Attributes are basically all the dimensions present in your data. But do all of them, in the raw format, represent the underlying trends you want to learn in the best way possible? Maybe not. So what you do in feature engineering, is pre-process your data so that your model/learning algorithm has to spend minimum effort on wading through noise. What I mean by ‘noise’ here, is any information that is not relevant to learning/predicting your ultimate goal. In fact, using good features can even let you use considerably simpler models since you are doing a part of the thinking yourself.
But as with any technique in Machine Learning, always use validation to make sure that the new features you introduce really do improve your predictions, instead of adding unnecessary complexity to your pipeline.

As mentioned before, good feature engineering involves intuition, domain knowledge (human experience) and basic math skills. So heres a few extremely simple techniques for you to (maybe) apply in your next data science solution:
1. Representing timestamps
Time-stamp attributes are usually denoted by the EPOCH time or split up into multiple dimensions such as (Year, Month, Date, Hours, Minutes, Seconds). But in many applications, a lot of that information is unnecessary. Consider for example a supervised system that tries to predict traffic levels in a city as a function of Location+Time. In this case, trying to learn trends that vary by seconds would mostly be misleading. The year wouldn’t add much value to the model as well. Hours, day and month are probably the only dimensions you need. So when representing the time, try to ensure that your model does require all the numbers you are providing it.
And not to forget Time Zones. If your data sources come from different geographical sources, do remember to normalize by time-zones if needed.
2. Decomposing Categorical Attributes
Some attributes come as categories instead of numbers. A simple example would be a ‘color’ attribute that is (say) one of {Red, Green, Blue}. The most common way to go about representing this, is to convert each category into a binary attribute that takes one value out of {0, 1}. So you basically end up with a number of added attributes equal to the number of categories possible. And for each instance in your dataset, only one of them is 1 (with the others being 0). This is a form of one-hot encoding.
If you are new to this idea, you may think of decomposition as an unnecessary hassle (we are essentially bloating up the dimensionality of the dataset). Instead, you might be tempted to convert the categorical attribute into a scalar value. For example, the color feature might take one value from {1, 2, 3}, representing {Red, Green, Blue} respectively. There are two problems with this. First, for a mathematical model, this would mean that Red is somehow ‘more similar’ to Green than Blue (since |1-3| > |1-2|). Unless your categories do have a natural ordering (such as stations on a railway line), this might mislead your model. Secondly, it would make statistical metrics (such as mean) meaningless – or worse, misleading yet again. Consider the color example again. If your dataset contains equal numbers of Red and Blue instances but no Green ones, the ‘average’ value of color might still come out to be ~2 – essentially meaning Green!
The safest place to convert a categorical attribute into a scalar, is when you have only two categories possible. So you have {0, 1} corresponding to {Category 1, Category 2}. In this case, an ‘ordering’ isn’t really required, and you can interpret the value of the attribute as the probability of belonging to Category 2 vs Category 1.
3. Binning/Bucketing
Sometimes, it makes more sense to represent a numerical attribute as a categorical one. The idea is to reduce the noise endured by the learning algorithm, by assigning certain ranges of a numerical attribute to distinct ‘buckets’. Consider the problem of predicting whether a person owns a certain item of clothing or not. Age might definitely be a factor here. What is actually more pertinent, is the Age Group. So what you could do, is have ranges such as 1-10, 11-18, 19-25, 26-40, etc. Moreover, instead of decomposing these categories as in point 2, you could just use scalar values, since age groups that lie ‘closer by’ do represent similar properties.
Bucketing makes sense when the domain of your attribute can be divided into neat ranges, where all numbers falling in a range imply a common characteristic. It reduces overfitting in certain applications, where you don’t want your model to try and distinguish between values that are too close by – for example, you could club together all latitude values that fall in a city, if your property of interest is a function of the city as a whole. Binning also reduces the effect of tiny errors, by ’rounding off’ a given value to the nearest representative. Binning does not make sense if the number of your ranges is comparable to the total possible values, or if precision is very important to you.
4. Feature Crosses
This is perhaps the most important/useful one of these. Feature crosses are a unique way to combine two or more categorical attributes into a single one. This is extremely useful a technique, when certain features together denote a property better than individually by themselves. Mathematically speaking, you are doing a cross product between all possible values of the categorical features.
Consider a feature A, with two possible values {A1, A2}. Let B be a feature with possibilities {B1, B2}. Then, a feature-cross between A & B (lets call it AB) would take one of the following values: {(A1, B1), (A1, B2), (A2, B1), (A2, B2)}. You can basically give these ‘combinations’ any names you like. Just remember that every combination denotes a synergy between the information contained by the corresponding values of A and B.
For example, take the diagram shown below:

All the blue points belong to one class, and the red ones belong to another. Lets put the actual model aside. First off, you would benefit from binning the X, Y values into {x < 0, x >= 0} & {y < 0, y >= 0} respectively. Lets call them {Xn, Xp} and {Yn, Yp}. It is pretty obvious that Quadrants I & III correspond to class Red, and Quadrants II & IV contain class Blue. So if you could now cross features X and Y into a single feature ‘Quadrant’, you would basically have {I, II, III, IV} being equivalent to {(Xp, Yp), (Xn, Yp), (Xn, Yn), (Xp, Yn)} respectively.
A more concrete/relatable example of a (possibly) good feature cross is something like (Latitude, Longitude). A common Latitude corresponds to so many places around the globe. Same goes for the Longitude. But once you combine Lat & Long buckets into discreet ‘blocks’, they denote ‘regions’ in a geography, with possibly similar properties for each one.
Sometimes, attributes can also be ‘combined’ into a single feature with simple mathematical hacks. In the above example, suppose you define modified features 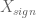
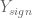


Now, you could just define a new feature 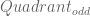
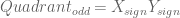
Thats all! If 
For sake of completeness, I will also mention some mathematically intensive feature engineering techniques, with links for you to read more about them:
5. Feature Selection : Using certain algorithms to automatically select a subset of your original features, for your final model. Here, you are not creating/modifying your current features, but rather pruning them to reduce noise/redundancy.
6. Feature Scaling : Sometimes, you may notice that certain attributes have a higher ‘magnitude’ than others. An example might be a person’s income – as compared to his age. In such cases, for certain models (such as Ridge Regression), it is infact necessary that you scale all your attributes to comparable/equivalent ranges. This prevents your model from giving greater weightage to certain attributes as compared to others.
7. Feature Extraction : Feature extraction involves a host of algorithms that automatically generate a new set of features from your raw attributes. Dimensionality reduction falls under this category.

Hi. Just to add to your point on feature scaling, it is needed when algorithm you are using involves measuring distance like linear regression or clustering. For algorithms like Random forest etc., you might not need it.
Great post! Very easy-to-understand explanations. Quick correction for your feature cross example: if Quadrant_even = -1 the class should be blue (not red).
Thanks for pointing that out 🙂
great post…..
This is the best content on feature engineering so far on the internet. Do you have any sources or books for me to learn more? Thank you!
Thanks! Feature engineering as a complete topic is handled very rarely in books. What you could do is google up some terms of interest you see in any posts on it, to learn more. Heres two links for you:
(Intro) http://machinelearningmastery.com/discover-feature-engineering-how-to-engineer-features-and-how-to-get-good-at-it/
(Technical) https://people.eecs.berkeley.edu/~jordan/courses/294-fall09/lectures/feature/slides.pdf
Fascinating article! This reminds me of something a Technical Writing professor taught me in University, a mandatory class I actually ended up enjoying very much, largely because of him. He said something that I’ve applied throughout my career. He says write about what you know, the information and facts you have, are the story. This applies very well to architecture, design, analysis, and communications. Another thought about not assigning numeric values to color. According to the electromagnetic spectrum, some colors are closer to others. Perhaps there’s a dimension there that could be explored, and certainly with radio spectrums in wireless communications.